Ethical Visualization in the Age of Big Data
A Planning Workshop Summary
A workshop to seek interdisciplinary expert perspectives on ethically and visually representing the historical place of misrepresented peoples and locales.
Contents
Session 4: Domain adaptation (for early modern French)
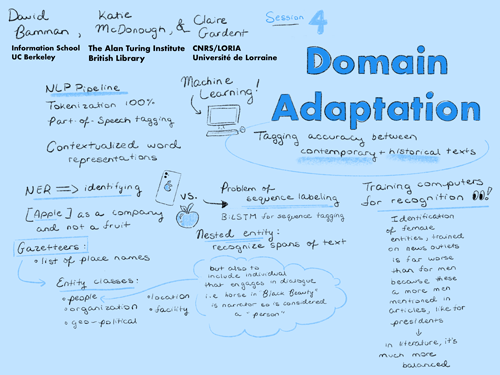
Scope and purpose
- Guiding question: What are the best practices when creating in-domain (early modern French) data for natural language processing and machine learning?
- Considerations:
Domain mismatch, validation, annotation tools, training a model (illustrated with NER) - Goal: Understanding the risks of out-of-the-box tools and how to overcome them by training new models with your own annotated datas
- Discussants:
David Bamman (lead), Katie McDonough & Claire Gardent
Documentation
- Listen:
Session 4 audio recording PART 1
Session 4 audio recording PART 2 - View: Session presentation slide deck
- Read: Session notes
- Briefing Documents:
- McDonough, Katherine, Ludovic Moncla, and Matje van de Camp. 2019. “Named entity recognition goes to old regime France: geographic text analysis for early modern French corpora”. International Journal of Geographical Information Science. 33 (12): 2498-2522.
- Bamman, David. Natural Language Processing for the Long Tail. Paper presented at Digital Humanities 2017.
- Azpeitia A., Cuadros M., Gaines S., and Rigau G. 2014. “NERC-fr: Supervised named entity recognition for French”. Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). 8655 LNAI: 158-165.
Discussion summary
Building on the previous session, this session addressed the applicability and accuracy of natural language processing across language domains. Most methods for natural language processing, including name entity recognition, are trained using the 1998 Wall Street Journal, which consequently yields highly accurate results for modern, journalistic American English (rates as high as 100% for tokenization and 98% for part of speech tagging). However, once those trained models are applied to other language domains (historic English, foreign languages), the accuracy declines precipitously to 40% to 60% accuracy, well below the threshold for making reliable analytic conclusions. Therefore, it is essential to create trained models within the language domain being studied, most preferably using proximate texts from the materials to be algorithmically analyzed. This means a great deal of discipline-specific work and human hours to create these datasets. We also discussed different methods for annotating such a dataset, as well as the various NLP methods that could be used.
Decisions
In our natural language processing workflow, we resolved to:
- restrict our algorithm to a maximum of five categories: people, physical places, metaphoric places, organizations, and events. Tracking more than locations in the text, will avoid replicating the militaristic ulterior motives inherent to the corpora themselves.
- use the BilSTM system of neural networks as a machine learning method,
- use BERT contextual embeddings, a Python library published by Google,
- employ the BRAT rapid annotation tool for creating the annotated data necessary for NLP training.
- use three datasets in the project:
- development data that is annotated,
- test data very similar to the corpus to evaluate the accuracy of the machine learning algorithm, and
- the actual corpus itself as the data that will be processed.